
Measures of Similarity and Distance
Pearson's Correlation Coefficient, Spearman's Correlation Coefficient, Euclidean Distance, Manhattan Distance


In statistics, a similarity measure is a real-valued function that quantifies the similarity between two objects. The purpose of a measure of similarity is to compare two vectors and compute a single number which evaluates their similarity. The main objective is to determine to what extent two vectors co-vary.
We will look at metrics that helps in understanding similarities by measures of correlation.
- Pearson's Correlation Coefficient
- Spearman's Correlation Coefficient
Let's take a look at each of these individually.
Pearson's Correlation Coefficient
Pearson's correlation coefficient is a measure related to the strength and direction of a linear relationship. The value for this coefficient will be between -1 and 1 where -1 indicates a strong, negative linear relationship and 1 indicates a strong, positive linear relationship.
If we have two vectors x and y, we can compare them in the following way to calculate Pearson's correlation coefficient:
where
$$\bar{x} = \frac{1}{n}\sum\limits_{i=1}^{n}x_i$$
or it can also be written as
$$CORR(x, y) = \frac{\text{COV}(x, y)}{\text{STDEV}(x)\text{ }\text{STDEV}(y)}$$
where
$$\text{STDEV}(x) = \sqrt{\frac{1}{n-1}\sum_{i=1}^{n}(x_i - \bar{x})^2}$$
and
$$\text{COV}(x, y) = \frac{1}{n-1}\sum_{i=1}^{n}(x_i - \bar{x})(y_i - \bar{y})$$
where n is the length of the vector, which must be the same for both x and y and $$\bar{x}$$ is the mean of the observations.
Function to get Pearson correlation coefficient.
def pearson_corr(x, y):
'''
Parameters
x - an array of matching length to array y
y - an array of matching length to array x
Return
corr - the pearson correlation coefficient for comparing x and y
'''
mean_x, mean_y = np.sum(x)/len(x), np.sum(y)/len(y)
x_diffs = x - mean_x
y_diffs = y - mean_y
corr_numerator = np.sum(x_diffs*y_diffs)
corr_denominator = np.sqrt(np.sum(x_diffs**2))*np.sqrt(np.sum(y_diffs**2))
corr = corr_numerator/corr_denominator
return corr
Spearman's Correlation coefficient
Spearman's correlation is non-parametric measure of rank correlation (statistical dependence between the rankings of two variables). It assesses how well the relationship between two variables can be described using a monotonic function.
The Spearman correlation between two variables is equal to the Pearson correlation between the rank values of those two variables; while Pearson's correlation assesses linear relationships, Spearman's correlation assesses monotonic relationships (whether linear or not).
You can quickly change from the raw data to the ranks using the .rank() method as shown code cell below.
If should map each of our data to ranked data values:
$$\textbf{x} \rightarrow \textbf{x}^{r}$$ $$\textbf{y} \rightarrow \textbf{y}^{r}$$
Here r indicate these are ranked values (this is not raising any value to the power of r). Then we compute Spearman's correlation coefficient as:
where
$$\bar{x}^r = \frac{1}{n}\sum\limits_{i=1}^{n}x^r_i$$
Function that takes in two vectors and returns the Spearman correlation coefficient.
def spearman_corr(x, y):
'''
Parameters
x - an array of matching length to array y
y - an array of matching length to array x
Return
corr - the spearman correlation coefficient for comparing x and y
'''
# Change each vector to ranked values
x = x.rank()
y = y.rank()
# Compute Mean Values
mean_x, mean_y = np.sum(x)/len(x), np.sum(y)/len(y)
x_diffs = x - mean_x
y_diffs = y - mean_y
corr_numerator = np.sum(x_diffs*y_diffs)
corr_denominator = np.sqrt(np.sum(x_diffs**2))*np.sqrt(np.sum(y_diffs**2))
corr = corr_numerator/corr_denominator
return corr
Measures of distance
- Euclidean Distance
- Manhattan Distance
Euclidean Distance
Euclidean distance is a measure of the straight line distance from one vector to another. In other words, euclidean distance is the square root of the sum of squared differences between corresponding elements of the two vectors. Since this is a measure of distance, larger values are an indicate two vectors are different from one another. The basis of many measures of similarity and dissimilarity is euclidean distance.
Euclidean distance is only appropriate for data measured on the same scale. Consider two vectors x and y, we can compute Euclidean Distance as:
$$ EUC(\textbf{x}, \textbf{y}) = \sqrt{\sum\limits_{i=1}^{n}(x_i - y_i)^2}$$
Function to Euclidean Distance. (I have taken help from numpy)
def eucl_dist(x, y):
'''
Parameters
x - an array of matching length to array y
y - an array of matching length to array x
Return
euc - the euclidean distance between x and y
'''
return np.linalg.norm(x - y)
Manhattan Distance
Different from euclidean distance, Manhattan distance is a 'manhattan block' distance from one vector to another. Therefore, imagine this distance as a way to compute the distance between two points when you are not able to go through buildings or blocks.
Specifically, this distance is computed as:
$$ MANHATTAN(\textbf{x}, \textbf{y}) = \sqrt{\sum\limits_{i=1}^{n}|x_i - y_i|}$$
Function to calculate Manhattan distance
def manhat_dist(x, y):
'''
INPUT
x - an array of matching length to array y
y - an array of matching length to array x
OUTPUT
manhat - the manhattan distance between x and y
'''
return sum(abs(e - s) for s, e in zip(x, y))
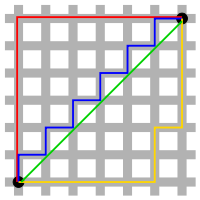
In the above image, the blue line gives the Manhattan distance, while the green line gives the Euclidean distance between two points.
Here in finding similarity by measure of distance, no scaling is performed in the denominator. Therefore, you need to make sure all of your data are on the same scale when using this metric.
Because measuring similarity is often based on looking at the distance between vectors, it is important in these cases to scale your data or to have all data be in the same scale.
It becomes a problem if some measures are on a 5 point scale, while others are on a 100 point scale, and we are most likely to have non-optimal results due to the difference in variability of features.